How JAR Embraced Cilium for Scalable, Secure Networking on EKS
12 min read · Written by Shreyank C M
Before diving deep into Cilium, let me give quick overview of Kubernetes Networking and the role of CNI Plugins. Kubernetes Networking and the Role of CNI Plugins Kubernetes, by design, abstracts away much of the underlying infrastructure to manage containers at scale. One of the most critical components of this

Before diving deep into Cilium, let me give quick overview of Kubernetes Networking and the role of CNI Plugins.
Kubernetes Networking and the Role of CNI Plugins
Kubernetes, by design, abstracts away much of the underlying infrastructure to manage containers at scale. One of the most critical components of this abstraction is networking. In a Kubernetes cluster, every pod (the basic unit of deployment) needs to communicate with other pods, services, and external systems, regardless of where they are scheduled in the cluster.
To achieve this, Kubernetes relies on a flexible networking model. This model mandates:
- Every pod has its own unique IP address.
- Pods can communicate with each other without NAT (Network Address Translation).
- Containers in a pod share the same network namespace.
- Nodes (hosts) must be able to route traffic to each other and to the pods.
This is where CNI (Container Network Interface) plugins come in. CNI is a specification that defines how networking for containers should be set up, attached, and maintained. These plugins are responsible for assigning IP addresses to pods, configuring network interfaces, and routing traffic within the cluster.
Several CNI plugins are available, each with its unique features and trade-offs:
- AWS default CNI: The out-of-the-box solution provided in Amazon EKS, which integrates tightly with AWS networking services like VPC.
- Calico: Known for its flexibility and network policy features.
- Flannel: A simpler solution, often used for smaller clusters.
- Cilium: A newer solution, leveraging eBPF for high performance, scalability, and deep observability.
The CNI plugin choice can significantly impact network performance, scalability, and security in a Kubernetes cluster. As JAR began scaling its infrastructure, we realized that the limitations of the default AWS CNI and kube-proxy became more apparent, leading us to explore alternatives like Cilium.
Why Kubernetes Networking is Critical for Large-Scale Cloud Environments
In a large-scale cloud environment, seamless and reliable networking is the backbone of an efficient Kubernetes cluster. As organizations like JAR scale their applications and services, the network becomes more complex, making the role of Kubernetes networking crucial for several reasons:
- Pod-to-Pod Communication: In Kubernetes, microservices running in different pods often need to communicate with each other. In large-scale environments, there can be hundreds or thousands of pods spread across multiple nodes, and ensuring reliable communication between them is vital. A robust networking layer allows each pod to get a unique IP and ensures they can communicate efficiently, regardless of where they are running in the cluster.
- Service Discovery and Load Balancing: In a microservices architecture, services need to discover and communicate with each other dynamically. Kubernetes provides service discovery and internal load balancing to distribute traffic evenly across healthy pods. In large cloud environments, where the number of services and traffic is high, the network needs to efficiently handle this dynamic communication while minimizing latency and overhead.
- Scalability: As applications scale, so does the number of containers, pods, and nodes in the cluster. Kubernetes networking must be scalable enough to handle the increased load, ensuring that even with thousands of microservices communicating, there are no bottlenecks or performance degradation. A robust network layer is essential to meet the demands of auto-scaling in response to traffic spikes or additional deployments.
- Security and Isolation: In a multi-tenant or highly segmented cloud environment, security becomes a critical concern. Kubernetes networking must provide the ability to isolate different workloads and enforce network policies for fine-grained access control. This ensures that sensitive workloads are properly isolated from each other while enabling secure communication between trusted services.
- High Availability and Resilience: A well-configured network ensures that even if nodes or pods fail, the traffic gets redirected to healthy instances without impacting the overall system. Kubernetes uses networking to support high availability by automatically rescheduling and redistributing traffic across the cluster. For large-scale cloud environments, where downtime can result in significant losses, resilient networking ensures continuity in the face of failures.
In essence, for any large-scale cloud deployment, the networking layer is foundational. It not only handles traffic between various services but also ensures performance, scalability, and security across the cluster. As we at JAR scaled our applications, the limitations of traditional CNI plugins became evident, leading us to re-evaluate and eventually adopt Cilium for its advanced capabilities.
The limitations of AWS’s default CNI and kube-proxy, which led JAR move to Cilium
1. IP Address Management and Scalability Issues:
- AWS’s VPC CNI allocates a set of IPs per node, which can quickly exhaust the available IPs within a VPC subnet, especially in large-scale clusters.
- This results in IP shortages, limiting the number of pods that can run on a node, which is a significant bottleneck for clusters running thousands of microservices. IPAM (IP Address Management) in the AWS CNI is tied to the number of Elastic Network Interfaces (ENIs) attached to each node, leading to complex scaling issues.
- Additionally, the overhead of managing ENIs and IP addresses affects performance and increases complexity, especially for bursty workloads.
2. Inefficient Traffic Routing with kube-proxy:
- kube-proxy relies on iptables or IPVS to manage network rules for service-to-service communication, but both methods come with performance trade-offs:
- iptables is known for slowing down as the number of services grows due to linear rule matching, leading to increased latency.
- As the number of services in the cluster grows, rule churn becomes a performance bottleneck. This can lead to network delays, connection drops, and inconsistent behavior, especially under heavy load.
- IPVS is slightly more efficient, but still doesn’t scale well with larger clusters and adds complexity to the environment.
3. Lack of Network Observability and Security:
- AWS’s default CNI offers limited visibility into the network, which makes it challenging to debug and monitor the network in a granular way.
- Security is another weak point, as the default CNI doesn’t have built-in features for fine-grained network policies or encryption. This makes it difficult to enforce security at the network layer without additional tools, like Calico or Cilium, to enforce policies or encryption.
4. Cross-Zone and Cross-Region Latency:
- AWS’s default CNI handles networking by routing traffic through VPC constructs, which can introduce latency issues, especially in cross-AZ or cross-region scenarios.
- In clusters spread across multiple availability zones, the traffic paths can become inefficient, introducing significant latency for internal service communication.
5. No Native Support for Load Balancing:
- While AWS does provide Elastic Load Balancers (ELBs), there is no native L4/L7 load balancing for internal services in the default CNI setup.
Why We Chose Cilium
As Kubernetes deployments grow in size and complexity, network performance, observability, and security become critical challenges. At JAR, we were facing issues that the default AWS CNI and kube-proxy could no longer handle efficiently. This led us to evaluate Cilium as a next-generation networking solution. Here’s why we chose Cilium for our Kubernetes clusters:
Introduction to Cilium
Cilium is an open-source networking, observability, and security solution built for Kubernetes. At its core, Cilium leverages eBPF (Extended Berkeley Packet Filter), which allows for high-performance and flexible packet processing within the Linux kernel. eBPF enables Cilium to bypass traditional IP routing and filtering mechanisms, providing both performance gains and advanced features. For us, this meant a fundamental shift in how our networking stack worked.
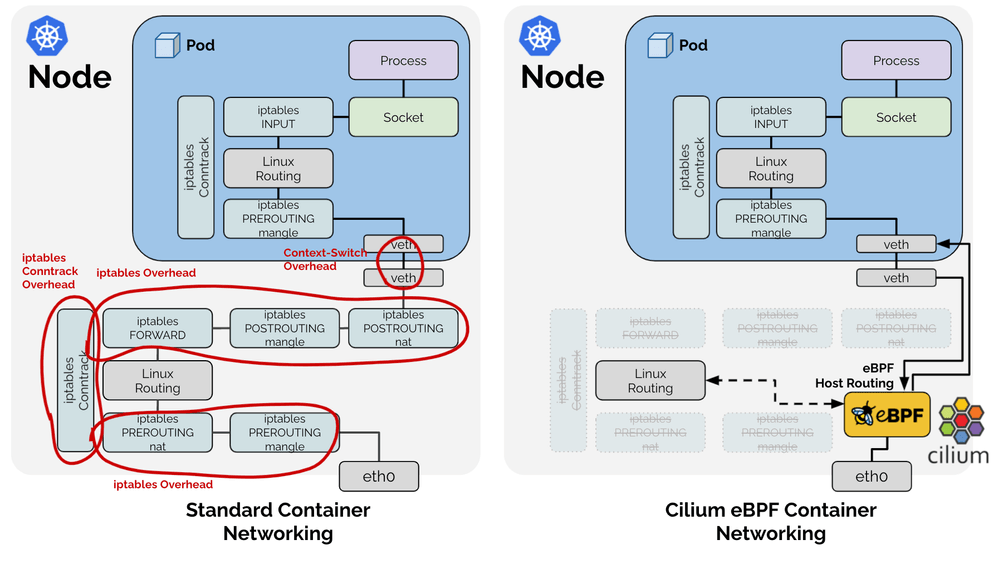
Why eBPF?
eBPF (Extended Berkeley Packet Filter) allows us to run sandboxed programs in the Linux kernel without needing to go back and forth between kernel space and user space (a limitation of traditional methods like iptables). The AWS default CNI and kube-proxy rely heavily on traditional methods like iptables for packet filtering and routing. As traffic increases and cluster sizes grow, these tools become bottlenecks due to inefficiencies in the way they handle packet traversal, rule lookups, and stateful inspection. eBPF, on the other hand, operates at the kernel level, offering several advantages:
- How eBPF Works: One of the most powerful features of the Linux kernel is that it allows us to dynamically load custom programs and execute them directly in kernel space. eBPF enables this by allowing developers to attach custom programs to various kernel hooks. These hooks can be placed at various points in the networking stack, such as when packets enter or exit the system.
- Flexibility: eBPF is programmable, meaning you can tailor it to perform specific actions on packets, like enforcing security policies, without the need for user-space context switching. This provides significant flexibility for enforcing advanced networking policies and improving visibility.
- Networking with eBPF: Instead of using
iptables(which operates in user space and can become inefficient with scale), eBPF allows us to attach programs directly to the network hooks in the kernel. This way, network packets can be processed more efficiently, bypassing the need for user space handling. - Scalability: Because eBPF operates at the kernel level, it scales efficiently across thousands of nodes, maintaining performance consistency.
These benefits made eBPF-powered Cilium an ideal solution for JAR’s growing infrastructure.
Key Features of Cilium
1. High Performance Cloud Native Networking (CNI):
- There are dozens of CNIs available for Kubernetes but, their features, scale, and performance vary greatly. Many of them rely on a legacy technology (iptables) that cannot handle the scale and churn of Kubernetes environments leading to increased latency and reduced throughput. Most CNIs also only offer support for L3/L4 Kubernetes network policy but little beyond. Many Cloud Provider have their own custom CNIs which results in operational complexity for customers operating in multi-cloud environments.
- Cilium’s control and data plane has been built from the ground up for large-scale and highly dynamic cloud native environments where 100s and even 1000s of containers are created and destroyed within seconds. Cilium’s control plane is highly optimized, running in Kubernetes clusters with 1,000s of nodes and 100K pods. Cilium’s data plane uses eBPF for efficient load-balancing and incremental updates, avoiding the pitfalls of large iptables rulesets.
- Cilium is built to scale. Whether you’re running a few nodes or managing a cluster with thousands, Cilium can handle it. Cilium’s eBPF-powered networking is optimized for large scale operations. This means you can grow your operations without worrying about the network becoming a bottleneck.
2. Kube-Proxy Replacement:
iptablesandNetfilterare the two foundational technologies of kube-proxy for implementing the Service abstraction. They carry legacy accumulated over 20 years of development grounded in more traditional networking environments that are typically far more static than your average Kubernetes cluster. In the age of cloud native, they are no longer the best tool for the job, especially in terms of performance, reliability, scalability, and operations.- If you already have kube-proxy running as a DaemonSet, transitioning to Cilium is a breeze. Replacing kube-proxy with Cilium is a straightforward process, as Cilium provides a Kubernetes-native implementation that is fully compatible with the Kubernetes API. Existing Kubernetes applications and configurations can continue to work seamlessly with Cilium.
- Cilium replaces kube-proxy with its eBPF-based approach, eliminating the overhead of
iptables. This results in more efficient load balancing and faster service-to-service communication. - Instead of iptables’ linear rule matching, Cilium leverages eBPF maps, ensuring near-instantaneous connection lookups, significantly improving service latency and reducing CPU usage.
For JAR, this meant a dramatic reduction in the time it took for new services to be discovered and routed, leading to faster deployment times and improved user experiences.
3. Advanced Network Policy Enforcement:
- Cilium supports the standard Kubernetes Network Policy out of the box but extends it with additional features and flexibility using Cilium Network Policies. These policies enable fine-grained control at Layers 3, 4, and 7 of the OSI model, providing more advanced use cases. This means more control over not just “who can talk to whom” but also over the content and nature of the traffic.
- This allowed us to enhance security in ways that AWS’s default CNI and kube-proxy couldn’t match. We could enforce security boundaries without sacrificing performance, leveraging eBPF for efficient policy enforcement.
- Cilium also integrates with Kubernetes’ native
NetworkPolicyresources, providing an easier transition from the existing setup but with more power and granularity.
4. Observability with Hubble:
- Hubble, Cilium’s observability platform, was another key factor in our decision-making. Before Hubble, understanding traffic flows, diagnosing latency issues, and ensuring security policies were working as expected was difficult.
- Hubble provides real-time monitoring of all network flows, DNS queries, and policy enforcement decisions, visualized through user-friendly dashboards. This helped us gain unparalleled visibility into what was happening inside our cluster.
- With Hubble, we could monitor dropped packets, trace connections between services, and quickly detect policy violations or misconfigurations.
- Having this observability built directly into Cilium allowed JAR to significantly reduce the time spent troubleshooting network issues and maintaining our security posture.
Cilium replaced everything that previously had anything to do with networking. In one sense, it’s just a CNI plugin, but on the other hand, it can also remove the need for so many other tools, like Kube-Proxy.
This combination of efficient packet processing, fine-grained policy control, and advanced observability provided by Cilium made it the ideal choice for JAR’s infrastructure. It not only solved the scaling and performance issues we encountered with the default AWS CNI but also gave us the tools to manage and secure our cluster more effectively.
Migration to Cilium in Production: Achieving Zero Downtime
Before rolling out Cilium into our production environment, I had to ensure that the process would be smooth, safe, and — most importantly — zero downtime. Here’s how we achieved that by leveraging a migration strategy inspired by Meltwater’s migration from AWS VPC CNI to Cilium.
Pre-Migration Testing
Before we dove into production, we ran extensive tests in isolated environments:
- Local testing: This helped us validate basic Cilium functionality on smaller clusters.
- Dummy staging: A replica of production but with dummy workloads, giving us confidence that the Cilium setup works at scale.
- Main staging: This environment mirrors production with actual workloads, ensuring Cilium would handle real-world traffic.
These testing environments allowed us to identify potential issues early, adjust configurations, and establish clear rollback plans if things went sideways.
Strategy for Production Migration
The key challenge for migrating in production was achieving zero downtime while replacing the AWS VPC CNI and kube-proxy. The idea was to stagger the migration by introducing Cilium only to new nodes, while the existing ones continued using the AWS VPC CNI and kube-proxy. Here’s how we pulled this off:
- Restricting AWS VPC CNI and kube-proxy to Existing Nodes:
- We constrained the
aws-nodeDaemonSet (AWS VPC CNI) andkube-proxyto only run on the existing nodes of the EKS cluster. - This ensures that any existing workloads would not be disrupted while new nodes were added to the cluster.
2. Introducing Cilium on New Nodes:
- Launched new nodes with Cilium as the only CNI by ensuring that the
ciliumDaemonSet ran exclusively on these new nodes. - These nodes were added to the cluster without interfering with the existing traffic handled by the AWS VPC CNI and kube-proxy.
3. Gradual Node Replacement:
- Once the new nodes were up and running with Cilium, we drained the old nodes (which still had AWS VPC CNI and kube-proxy running).
- This process gradually rescheduled the pods from the old nodes to the new ones, now powered solely by Cilium.
When we tested Cilium, we never had issues. We installed it with a Helm chart and only needed to change eight or ten lines in the values.yaml for Helm, and that’s all the configuration we needed.
Final Steps
Once the migration was complete, we deleted the AWS VPC CNI (aws-node DaemonSet) and kube-proxy from the cluster. With this, Cilium became the sole CNI, handling all network traffic across the production environment.
What’s Next
As we continue to evolve our networking infrastructure, there are several exciting developments on the horizon that will enable us to further enhance security, scalability, and ease of management:
1. Security with Tetragon
One area we’re particularly excited about is the integration of Tetragon for security. Tetragon, with its powerful runtime detection and enforcement capabilities, will give us enhanced visibility and control over security policies within our Kubernetes clusters. It’s something we’ll look at closely to bolster our internal security posture.
2. BGP and Cluster Mesh
Looking ahead, we’re also considering leveraging BGP (Border Gateway Protocol) to improve routing and inter-cluster communication. Combining BGP with Cilium’s Cluster Mesh capabilities opens up the possibility of meshing together multiple clusters. This would allow us to achieve better traffic management and redundancy across geographically distributed environments.
3. Maglev Consistent Hashing
Maglev Consistent Hashing is another feature on our radar. It offers improved load balancing, and when paired with cluster mesh, it could greatly enhance traffic distribution and reliability across multiple clusters. This would ensure that services are balanced efficiently, even across complex, multi-cluster setups.
4. Integrated Ingress with Envoy and Gateway API
Another exciting development is Cilium’s integration of ingress via Envoy. In addition, the ongoing integration with the Kubernetes Gateway API represents a shift toward simplifying our stack. Instead of needing multiple solutions to handle networking, observability, and security, Cilium allows us to consolidate these functionalities into a single tool. With this setup, the installation of just one piece of software — Cilium — provides CNI networking, network policies, observability, and Layer 7 traffic management.
5. NetKit and eBPF Host-Routing
As part of our next steps at JAR, we’re exploring the use of eBPF Host-Routing to fully bypass iptables and the upper host stack, and to achieve a faster network namespace switch compared to regular veth device operation. Even when network routing is performed by Cilium using eBPF, by default network packets still traverse some parts of the regular network stack of the node. This ensures that all packets still traverse through all of the iptables hooks in case you depend on them. However, they add significant overhead