

A self-recovering ticketing system architecture to improve our Lending funnel conversion?
This is in the context of our Lending business, which consists of multiple steps among multiple interacting systems both internal, and external third party systems to process one successful loan, which we refer as lending system workflow internally. Sharing our learnings, and journey towards building our in-house ticketing system.
Problem Statement
Workflow systems are essential for executing tasks in a predefined sequence, with each step depending on the successful completion of the previous one. Effective monitoring of these systems is crucial to ensure smooth operations and timely issue resolution. Key monitoring requirements include:
- Step-level Failure and Recovery: Detecting failures at each step of the workflow and initiating recovery processes promptly.
- User-level Success Metric: Tracking the success metric for individual users to identify potential issues affecting similar user groups.
- Turnaround Time Measurement: Measuring the time taken to complete each workflow, which is critical for performance analysis and SLA adherence.
Preliminary solutions
1. Jira Automation
Initially, we used Jira to manage workflow issues by creating a ticket for each user stuck at a step.
Issues:
- Ticket Spam: Dependency downtimes led to a flood of Jira tickets, overwhelming the system.
- Workflow Overhead: Creating tickets within the main application flow added unnecessary complexity and overhead.
- Unresolved Tickets: Tickets remained unresolved if users did not return to complete the workflow, cluttering the system with outdated issues.
2. Slack Integration
Next, we integrated Slack to send alerts for workflow step failures directly to relevant channels.
Issues:
- Alert Spam: Channels were quickly spammed with alerts, making it hard to identify critical issues.
- No Resolution Tracking: There was no mechanism to track the resolution of issues, leading to poor follow-up.
- Lack of Trackability: It was challenging to track the history and resolution status of issues over time.
Solution that worked
Concept
We conceptualised a decoupled monitoring service to address the limitations of previous solutions:
- Real-time Monitoring: The service continuously observes the database for real-time issue detection at each workflow step.
- SLA Breach Alerts: Alerts are generated when Service Level Agreements (SLAs) are breached, ensuring timely attention to critical issues.
- Escalation Management: The service updates escalation levels for unresolved issues based on customised SLA parameters.
- Automated Resolution: A resolver feature attempts to resolve issues in real-time by querying the database.
Architecture
The architecture of the monitoring service is designed to be modular and scalable, with clear separation of concerns for each component.
Key system components
- Django Web Framework:
- Provides the core application framework.
- Manages the database models, views, and REST API endpoints.
- Serves as the interface for users to interact with the monitoring service.
- Celery and Celery Beat:
- Celery: A distributed task queue system that handles the asynchronous execution of tasks.
- Celery Beat: A scheduler that triggers periodic tasks in Celery.
- Redis: Acts as the message broker and result backend for Celery, ensuring fast and reliable task queuing and processing.
- PostgreSQL Database:
- Stores workflow data, alerts, and escalation statuses.
- Provides a reliable and scalable storage solution.
Task scheduling with Celery and Celery Beat
- Celery Configuration:
- Celery is configured to use Redis as the message broker. This involves setting up Redis and pointing Celery to use it for sending and receiving task messages.
- Tasks are defined in Django applications and registered with Celery.
- Celery Beat Scheduler:
- Celery Beat is configured to schedule tasks at defined intervals. The schedule can be customized based on the monitoring requirements.
- The tasks include Watchers, Validators, and Resolvers, which are responsible for different aspects of monitoring and resolution.
- Redis Integration:
- Redis is used for queuing tasks and storing task results.
- When a task is scheduled by Celery Beat, it is placed in the Redis queue.
- Celery workers pick up tasks from the Redis queue and execute them asynchronously.
Alerts Journey
The alert journey outlines the states an alert transitions through from initiation to resolution.
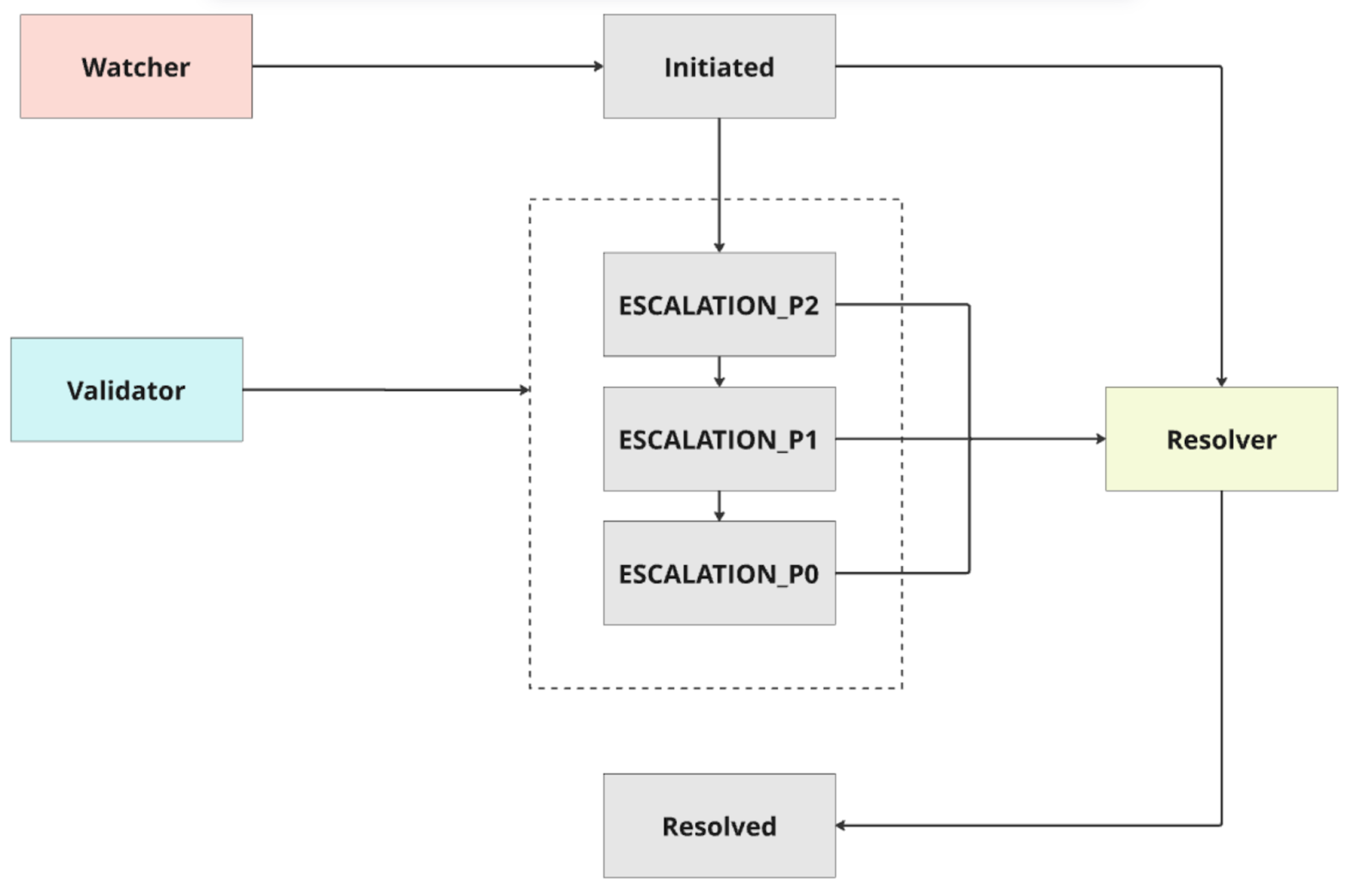
- Initiated:
- State: INITIATED
- Trigger: Watcher detects a workflow step failure.
- Action: An alert is created in the database with the status INITIATED.
- Escalation P2:
- State: ESCLATION_P2
- Trigger: Validator detects that the alert has not been resolved within the initial SLA threshold.
- Action: The alert status is updated to escalation ESCLATION_P2, indicating an escalation to priority level 2.
- Stakeholders: Support Team
- Escalation P1:
- State: ESCLATION_P1
- Trigger: Validator detects that the alert has not been resolved within the next SLA threshold.
- Action: The alert status is updated to ESCLATION_P1, indicating an escalation to priority level 1.
- Stakeholders: Tech Teams
- Escalation P0:
- State: ESCLATION_P0
- Trigger: Validator detects that the alert has not been resolved within the final SLA threshold.
- Action: The alert status is updated to ESCLATION_P0, indicating an escalation to priority level 0.
- Stakeholders: Product Teams.
- Resolved:
- State: RESOLVED
- Trigger: Resolver successfully addresses the issue, or the issue is manually resolved by a user.
- Action: The alert status is updated to RESOLVED, indicating that the issue has been resolved.
Workflow of Task Execution
- Watchers:
- Periodically query the database to detect any step-level failures in the workflows.
- Generate alerts if a failure is detected and store the alert information in the database.

- Validators:
- Periodically check the status of unresolved alerts.
- Update the escalation status of alerts based on predefined SLA parameters.

- Resolvers:
- Attempt to automatically resolve issues by interacting with the application database.
- If successful, update the alert status to resolved.

Technology Stack
- Framework: Django provides a robust and scalable web framework for building the monitoring service.
- Programming Language: Python is used for its simplicity and extensive libraries.
- Task Queue and Scheduler: Celery and Celery Beat manage task scheduling and execution efficiently.
- Database: PostgreSQL serves as the reliable and scalable database for storing monitoring data.
- Message Broker: Redis is used to manage the Celery task queue and store task results.
Benefits
- Decoupled Monitoring: Separates monitoring from the main application, reducing overhead and complexity.
- Simplicity: Easy to develop and maintain, with a clear focus on monitoring and alerting.
- Quantified Alerts: Provides measurable and actionable alerts for better issue management.
- Meaningful Metrics: Delivers insightful metrics on workflow performance and issue resolution.
Future Scope
- Integration with On-call Roster: Integrate the monitoring service with on-call systems to ensure that relevant personnel are notified immediately when critical issues arise. This can improve response times and resolution rates.
- Scalability with Distributed Tasks: Enhance the system's scalability by distributing scheduled tasks across multiple nodes. This will allow the service to handle higher loads and process alerts faster, making it suitable for large-scale workflow systems.
- Advanced Analytics: Develop detailed dashboards and reporting tools to provide deeper insights into system performance. This can help identify trends, bottlenecks, and areas for improvement, leading to more informed decision-making.
- Customizable Alerting: Offer more granular control over alerting mechanisms, allowing administrators to set specific thresholds and escalation policies for different workflow steps. This can help tailor the monitoring service to the unique needs of various workflows.
By implementing these future enhancements, the monitoring service can become more robust, intelligent, and scalable. It will be better equipped to handle complex workflow requirements, provide deeper insights into system performance, and ensure higher reliability and efficiency.